Shopify Quiz Builder vs. LLMs: Why Purpose-Built Wins for Product Recommendations
- Apr 6
- 8 min read

More Shopify merchants are experimenting with AI chatbots and general-purpose language models to handle on-site product quizzes. The appeal is obvious – why pay for a dedicated tool when something like ChatGPT or Claude already exists? The gap between what a specialized Shopify quiz builder delivers and what an LLM can realistically pull off, however, becomes clear the moment store complexity grows beyond a handful of products.
This article breaks down exactly where that gap appears – in recommendation quality, setup burden, and long-term maintenance – so merchants can make an informed decision before committing to either route.
What Makes a Product Quiz Actually Work?
The common assumption is that building a quiz is mostly about asking the right questions in a visually appealing way. In practice, that's the straightforward part. Any competent quiz builder Shopify merchants can install from the app store can handle question configuration with an appealing template in a matter of minutes.
The harder challenge is everything downstream. Once a shopper answers, the quiz needs to map those responses to specific products with accuracy – accounting for multiple conditions, overlapping criteria, and edge cases that real shoppers inevitably hit. That's where most DIY and LLM-based setups begin to show cracks.
The Two Approaches: Dedicated Platform vs. LLM Prompt
A purpose-built Shopify quiz builder comes with nuanced recommendation logic already structured into the platform. The merchant configures answer paths; the platform routes them to the right products. There's no guesswork, no probability – the logic is deterministic.
An LLM-based setup works differently. The merchant writes a system prompt instructing the model how to interpret quiz answers and return a suggestion. It can produce results. Whether those results are consistently accurate is a separate question – and a harder one to answer.
The distinction matters more than it looks. Writing a prompt is not the same as building structured recommendation logic, and the difference shows in conversion rates.
How Visual Quiz Builder's Recommendation Engine Works
Visual Quiz Builder offers several recommendation algorithms, each suited to different catalog structures and quiz designs. The “Most Likely” algorithm is score-based: answers accumulate weighted points toward products or outcomes, and the highest scorer wins. “Perfect Match” surfaces only products that satisfy every selected criterion – no partial matches.
“Outcome-Based” is a more nuanced scoring approach where the merchant defines discrete outcomes (such as a “sensitive skin” or “performance athlete” profile) and answers push the shopper toward the best-fit outcome, which then maps to specific products or collections. Finally, the “AI” algorithm uses machine learning to match answers to products based on semantic relevance across the catalog. The merchant chooses the algorithm that fits the quiz – the platform executes it reliably.

This is the core difference between a purpose-built tool and a general-purpose AI. One is engineered for structured product routing; the other is engineered for language generation.
AI-Assisted Tagging: Controlled and Catalog-Aware
VQB does use AI internally – but in a tightly scoped way. Its AI-assisted tagging links quiz answers to relevant products based on actual store data, not open-ended interpretation. The model isn't given free rein; it's applied to a specific, bounded task tied to the merchant's real inventory.

Giving a general LLM that same job without structure is a different situation entirely. A language model reasoning about products it hasn't been trained on, from a catalog it can't access in real time, produces outputs that are plausible – not necessarily accurate.
What This Looks Like in Practice: Two Real Examples
Two brands using Visual Quiz Builder illustrate what outcome-based logic can do at scale:
Function of Beauty's hair quiz handles genuinely complex, multi-variable logic – calculating hair damage scores, factoring in overlapping user inputs, and producing personalized recommendations that account for combinations most rule-based systems would struggle with. This is VQB's outcome framework running at a meaningful scale.

SKOON's skin assessment demonstrates how lifestyle-informed data – skin type, daily routine, environmental factors – can feed into product matching without sacrificing precision. The results feel tailored rather than categorical.

Neither outcome would be reproducible by prompting a general LLM with a product list and expecting structured, reliable results.
What Building a Quiz with an LLM Actually Requires
To be direct: LLMs like ChatGPT and Claude (or apps like Replo that are a wrapper on an LLM) can handle quiz experiences with straightforward selection criteria and get passable results using a well-crafted prompt. That's a real use case, and it's worth acknowledging.
The limitations surface quickly once complexity increases. Here's what merchants attempting an LLM-based quiz typically encounter:
Prompt engineering burden. Getting reliable recommendations requires writing a system prompt that accounts for every possible input combination – and revising it every time something breaks.
Manual testing at scale. Every logic path needs to be verified by hand. There's no built-in validation, no error flag when the model returns a product that doesn't exist or has been discontinued.
Accuracy verification falls on the merchant. The merchant needs enough product knowledge to catch the mistakes the model makes confidently – and it will make them.
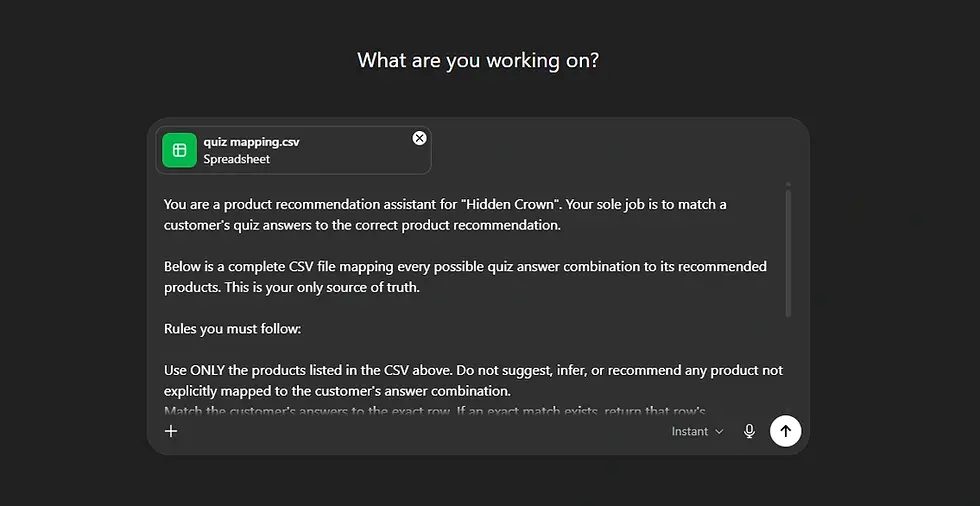
Pro tip: Before committing to an LLM-based quiz setup, map out every possible answer combination across your quiz. If that list runs into the dozens or hundreds, a language model prompt is almost certainly the wrong tool for the job. One way to reduce errors: feed the LLM a CSV that maps every outcome and its corresponding products, rather than asking the model to reason from scratch. This gives the model a ground-truth reference to constrain its responses – but it doesn’t eliminate the need to verify outputs, and it still requires the merchant to maintain that mapping as the catalog evolves.
How Inaccurate Recommendations Affect Revenue
Research compiled by Marketing LTB further shows that interactive product quizzes typically increase conversion rates by 10–30% compared to generic product pages. That lift depends entirely on recommendation accuracy. A quiz returning subtly wrong product suggestions doesn't just fail to convert – it erodes the trust that brings shoppers back.
The Maintenance Problem Most Merchants Overlook
Setting up a quiz is a project with a start date. Keeping it accurate after six, nine, or twelve months of catalog changes is an ongoing operational reality that rarely gets factored into the initial build decision.
How VQB Stays in Sync with Store Changes
When products are added, updated, or discontinued in a Shopify merchant’s store, VQB's native Shopify integration propagates those changes to its backend and to quiz recommendations automatically. The quiz a merchant builds in January returns accurate results in October without manual intervention.
VQB also stores a significant volume of events tied to every quiz interaction, surfacing the relevant metrics directly in its analytics dashboard. This is one area where a dedicated Shopify quiz builder app has a structural advantage that's easy to overlook at setup time.
When a merchant has a specific question, the standard analytics view doesn't surface immediately – say, which answer combination most often precedes a high-value order – VQB can process historical event data to find the answer. With an LLM-based setup, if that event wasn't tracked at build time, the data simply doesn't exist.
How LLM-Based Quizzes Break (Silently)
This is the part that rarely shows up in comparison articles. When a Shopify catalog changes and an LLM-based quiz hasn't been updated to match, nothing announces the problem. The quiz keeps running, recommending products that may no longer exist or applying logic built around attributes that have since changed.
The merchant finds out one of three ways:
A customer reports a recommendation that doesn't match what's actually in the store
A support inquiry arrives about a product the quiz suggested, but that can't be found
Conversion data slides quietly and the cause isn't immediately obvious
There's no alert. No automatic fix. The merchant built it, so the merchant debugs it.
Feature | Visual Quiz Builder | LLM-Based Quiz Setup |
Recommendation logic | Deterministic + Probabilistic | Probabilistic, prompt-dependent |
Shopify catalog sync | Automatic | Manual or custom-built |
Catalog change handling | Real-time propagation | Silent failure until discovered |
Analytics & event tracking | Built-in, historical | Only what was tracked at build time |
Setup expertise required | No-code, merchant-friendly | Prompt engineering + technical integration |
Customer support | Dedicated team | None |
Accuracy testing | Built into the platform | Fully manual |
Customer Support: Often the Deciding Factor
When something breaks in a VQB quiz, there's a support team that knows the product and can troubleshoot in context. That sounds unremarkable until the alternative is debugging a misbehaving LLM integration without documentation, without a support channel, and without a clear path to diagnosis. The merchant built it; the merchant fixes it.
When Is an LLM Actually Enough?
Yes, there are cases where an LLM quiz is sufficient. A store with a few dozen stable products, simple recommendation criteria, and no expansion plans doesn't need a purpose-built platform. A basic prompt-based setup covers that ground without over-engineering the solution.
Beyond that point, the trade-offs stack up fast:
More products mean more logic paths to account for
More logic paths require more complex, fragile prompts to maintain
More catalog changes create more silent breakage risk
More breakage risk means more time spent debugging instead of selling
For merchants who want the quiz to function as a reliable revenue engine rather than a recurring technical task, a quiz builder Shopify merchants can deploy once and trust to run is the more predictable choice. Ecommerce benchmarks for 2025–2026 show the top 20% of Shopify stores reaching conversion rates of 3.2% or higher – a gap that product quizzes are well-positioned to help close, provided the recommendation logic is sound.
Why Visual Quiz Builder Is the Stronger Long-Term Choice
Three things separate a purpose-built Shopify quiz builder from an LLM-based setup for anyone beyond the simplest use cases:
Recommendation logic that works from day one. No manual edge-case testing, no uncertainty about whether outputs are correct. VQB's score-based and outcome-based framework has been refined across thousands of stores and multiple product categories.
Native Shopify sync that requires no ongoing maintenance. Catalog changes flow through automatically. A quiz built today stays accurate for months from now without anyone touching it.
Dedicated support when something doesn't behave as expected. There's a team behind the product that understands how the logic works – and can help resolve issues that would otherwise require merchants to debug a black box alone.
For stores serious about turning product discovery into a conversion channel, the question isn't whether to use a quiz – it's whether to build one that actually holds up over time.
Ready to see what a purpose-built quiz delivers for your store? Start building with Visual Quiz Builder and replace guesswork with structured, catalog-connected recommendations that hold up as the catalog changes.
Frequently Asked Questions
Can ChatGPT or Claude build a product recommendation quiz for a Shopify store?
Yes, technically – but getting catalog-aware, reliable recommendations requires significant prompt engineering, manual testing, and custom Shopify integration. The results are harder to verify and harder to maintain than they first appear.
How does Visual Quiz Builder's recommendation logic differ from a general-purpose AI chatbot?
VQB's algorithms are purpose-built for ecommerce. They map quiz answers directly to specific products, collections, or variants using structured outcome logic – not probabilistic text generation that approximates the right answer. The core difference is reliability.
What happens to an LLM-based quiz when the product catalog changes?
Nothing automatic. The model doesn't know the catalog has changed. Recommendations may reference discontinued products or use outdated logic until someone manually updates the prompt – if they catch the problem at all.
Do merchants need technical skills to set up a quiz on Visual Quiz Builder?
No. VQB is a Shopify quiz builder designed for non-technical merchants, with a no-code builder, pre-built logic templates, and native Shopify integration. AI-assisted tagging further reduces setup time by automatically linking answers to relevant products from the store's catalog.
How does VQB handle analytics compared to an LLM-based quiz?
VQB captures and stores a wide range of quiz interaction events, making it possible to analyze performance – including answering historical questions – well after the quiz launches. An LLM-based setup only has data for events the merchant thought to track at build time. Everything else is gone.


